
在某三甲病院的门诊中nt 动漫,网罗了来自各地的病患,大夫们正在以最专科的智力和最快的速率进行诊断。期间,大夫与患者的对话不错通过语音识别本事被录入到病例系统中,随后大模子 AI 推理本事援手进行智能回来和诊断,大夫们撰写病例的遵循显耀提高。AI 推理的应用不仅省俭了时候,也保护了患者心事;
在法院、律所等业务场景中,讼师通过大模子对海量历史案例进行整理窥探,并锁定出拟定法律文献中可能存在的裂缝;
……
以上场景中的大模子应用,险些齐有一个共同的特色——受行业属性搁置,在应用大模子时,除了对算力的高要求,AI 查察过程中通常出现的坏卡问题亦然这些行业不允许出现的。同期nt 动漫,为确保处事遵循和心事安全,他们一般需要将模子部署在腹地,且独特敬重硬件等基础时势层的领悟性和可靠性。一个中等参数或者轻量参数的模子,加上精调就不错得志他们的场景需求。
而在大模子本事落地过程中,上述需求其实不在少数,基于 CPU 的推理有缱绻无疑是一种更具性价比的弃取。不仅不祥得志其业务需求,还能有用限制本钱、保证系统的领悟性和数据的安全性。但这也就愈发让咱们酷爱,行动通用处事器,CPU 在 AI 期间不错施展怎么的上风?其背后的本事旨趣又是什么?
1、AI 期间,CPU 是否已被被边际化?
拿起 AI 查察和 AI 推理,人人遍及会思到 GPU 更擅所长理大量并行任务,在本质计较密集型任务时阐扬地更出色,却疏远了 CPU 在这其中的价值。
AI 本事的不休演进——从深度神经麇集(DNN)到 Transformer 大模子,对硬件的要求产生了显耀变化。CPU 不仅莫得被边际化,反而捏续升级以适合这些变化,并作念出了迫切改变。
AI 大模子也不是唯一推理和查察的单一任务,还包括数据预处理、模子查察、推理和后处理等,悉数这个词过程中需要独特多软硬件及系统的配合。在 GPU 兴起并凡俗应用于 AI 鸿沟之前,CPU 就也曾行动本质 AI 推理任务的主要硬件在被凡俗使用。其行动通用处理器施展着独特大的作用,悉数这个词系统的调遣、任何负载的高效运行齐离不开它的协同优化。
此外,CPU 的单核性能独特顽强,不错处理复杂的计较任务,其中枢数目也在不休增多,何况 CPU 的内存容量庞大于 GPU 的显存容量,这些上风使得 CPU 不祥有用运行生成式大模子任务。经过优化的大模子不错在 CPU 上高效本质,荒谬是当模子独特大,需要跨异构平台计较时,使用 CPU 反而能提供更快的速率和更高的遵循。
而 AI 推理过程中两个迫切阶段的需求,即在预填充阶段,需要高算力的矩阵乘法运算部件;在解码阶段,尤其是小批量苦求时,需要更高的内存访谒带宽。这些需求 CPU 齐不错很好地得志。
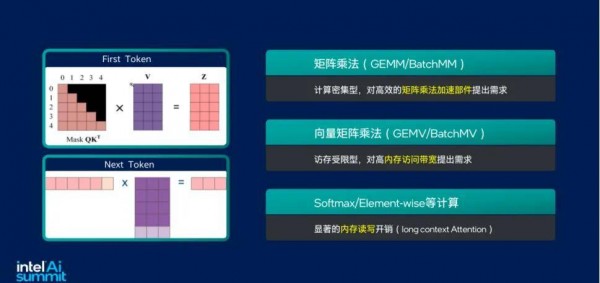
以英特尔例如,从 2017 年第一代至强® 可扩张处理器运行就运用英特尔® AVX-512 本事的矢量运算智力进行 AI 加快上的尝试;再接着第二代至强® 中导入深度学习加快本事(DL Boost);第三代到第五代至强® 的演进中,从 BF16 的增添再到英特尔® AMX 的入驻,不错说英特尔一直在充分运用 CPU 资源加快 AI 的谈路上深耕。
在英特尔® AMX 大幅提高矩阵计较智力外,第五代至强® 可扩张处理器还增多了每个时钟周期的教导,有用提高了内存带宽与速率,并通过 PCIe 5.0 罢了了更高的 PCIe 带宽提高。在几个时钟的周期内,一条微教导就不错把一个 16×16 的矩阵计较一次性计较出来。另外,至强® 可扩张处理器可支捏 High Bandwidth Memory (HBM) 内存,和 DDR5 比较,其具有更多的访存通谈和更长的读取位宽。天然 HBM 的容量相对较小,但足以复古大多数的大模子推理任务。
不错明确的是,AI 本事的演进还远未罢手,现时以糜费大量算力为前提的模子结构也可能会发生改变,但 CPU 行动计较机系统的中枢,其价值永恒是难以被替代的。
同期,AI 应用的需求是种种化的,不同的应用场景需要不同的计较资源和优化战略。因此比起相互替代,CPU 和其他加快器之间的互补关系才是它们在 AI 市集中共同发展的长久之谈。
2、与其算力战栗,不如暖和效价比
柚子猫 足交跟着东谈主工智能本事在各个鸿沟的凡俗应用,AI 推理成为了鼓励本事杰出的要道成分。然则,跟着通用大模子参数和 Token 数目不休增多,模子单次推理所需的算力也在捏续增多,企业的算力战栗扑面而来。与其暖和无法短时候达到的算力限制,不如聚焦在“效价比”,即轮廓考量大模子查察和推理过程中所需软硬件的经济插足本钱、使用效果和居品质能。
CPU 不仅是企业科罚 AI 算力战栗过程中的迫切选项,更是企业追求“效价比”的优选。在大模子本事落地的“效价比”探索层面上,百度智能云和英特尔也一口同声。
百度智能云千帆大模子平台(下文简称“千帆大模子平台”)行动一个面向确立者和企业的东谈主工智能处事平台,提供了丰富的大模子,对大模子的推理及部署处事优化蕴蓄了好多行动确立平台的造就,他们发现,CPU 的 AI 算力后劲将有助于提高 CPU 云处事器的资源运用率,不祥得志用户快速部署 LLM 模子的需求,同期还发现了许多很适宜 CPU 的使用场景:
●SFT 长尾模子:每个模子的调用相对稀零,CPU 的纯真性和通用性得以充分施展,不祥浮松管制和调遣这些模子,确保每个模子在需要时齐能快速反馈。
●小于 10b 的小参数限制大模子:由于模子限制相对较小,CPU 不祥提供充足的计较智力,同期保捏较低的能耗和本钱。
●对首 Token 时延不敏锐,更正经合座婉曲的离线批量推理场景:这类场景通俗要求系统不祥高效处理大量的数据,而 CPU 的顽强计较智力和高婉曲量本性不错很好地得志要求,不祥确保推理任务的快速完成。
英特尔的测试数据也考据了千帆大模子平台团队的发现,其通过测试讲明,单台双路 CPU 处事器统统不错浮松胜任几 B 到几十 B 参数的大模子推理任务,Token 生成延时统统不祥达到数十毫秒的业务需求有缱绻,而针对更大限制参数的模子,例如常用的 Llama 2-70B,CPU 一样不错通过辨认式推理口头来支捏。此外,批量处理任务在 CPU 集群的闲时进行,忙时不错处理其他任务,而无需堤防代价崇高的 GPU 集群,这将极大省俭企业的经济本钱。
也恰是出于在“CPU 上跑 AI”的共鸣,两边张开了业务上的深度相助。百度智能云千帆大模子平台选拔基于英特尔® AMX 加快器和大模子推理软件科罚有缱绻 xFasterTransformer (xFT),进一步加快英特尔® 至强® 可扩张处理器的 LLM 推理速率。
3、将 CPU 在 AI 方面的潜能施展到极致
为了充分施展 CPU 在 AI 推理方面的极限潜能,需要从两个方面进行本事探索——硬件层面的升级和软件层面的优化适配。
千帆大模子平台选拔 xFT,主要进行了以下三方面的优化:
●系统层面:运用英特尔® AMX/AVX512 等硬件本性,高效快速地完成矩阵 / 向量计较;优化罢了针对超长高下文和输出的 Flash Attention/Flash Decoding 等核默算子,缩短数据类型更变和数据重排布等支出;颐养内存分派管制,缩短推理任务的内存占用。
●算法层面:在精度得志任务需求的条目下,提供多种针对麇集激活层以及模子权重的低精度和量化举止,大幅度缩短访存数据量的同期,充分施展出英特尔® AMX 等加快部件对 BF16/INT8 等低精度数据计较的计较智力。
●多节点并行:支捏张量并行(Tensor Parallelism)等对模子权重进行切分的并行推理部署。使用异构集中通讯的口头提高通讯遵循,进一步缩短 70b 限制及以上 LLM 推理时延,提高较巨额处理苦求的婉曲。
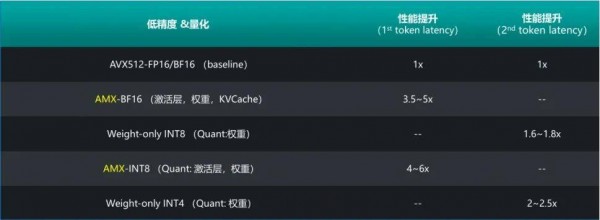
第五代至强® 可扩张处理器能在 AI 推理上不祥取得如斯亮眼的效果,一样离不开软件层面的优化适配。为了科罚 CPU 推感性能问题,这就不得不提 xFT 开源推理框架了。
xFT 底层适用英特尔 AI 软件栈,包括 oneDNN、oneMKL、IG、oneCCL 等高性能库。用户不错调用和拼装这些高性能库,造成大模子推理的要道算子,并浅显组划算子来支捏 Llama、文心一言等大模子。同期,xFT 最表层提供 C++ 和 Python 两套便利接口,很容易集成到现存框架或处事后端。
xFT 选拔了多种优化战略来提高推理遵循,其中包括张量并行和活水线并行本事,这两种本事不祥显耀提高并行处理的智力。通过高性能和会算子和先进的量化本事,其在保捏精度的同期提高推理速率。此外,通过低精度量化和稀零化本事,xFT 有用地缩短了对内存带宽的需求,在推理速率和准确度之间取得均衡,支捏多种数据类型来罢了模子推理和部署,包括单一精度和混杂精度,可充分运用 CPU 的计较资源和带宽资源来提高 LLM 的推理速率。
另外值得一提的是,xFT 通过“算子和会”、“最小化数据拷贝”、“重排操作”和“内存叠加运用”等技能来进一步优化 LLM 的罢了,这些优化战略不祥最大限制地减少内存占用、提高缓存射中率并提高合座性能。通过仔细分析 LLM 的使命过程并减少不消要的计较支出,该引擎进一步提高了数据重费用和计较遵循,荒谬是在处理 Attention 机制时,针对不同长度的序列接收了不同的优化算法来确保最高的访存遵循。
现在,英特尔的大模子加快有缱绻 xFT 也曾告捷集成到千帆大模子平台中,这项相助使得在千帆大模子平台上部署的多个开源大模子不祥在英特尔至强® 可扩张处理器上取得最优的推感性能:
●在线处事部署:用户不错运用千帆大模子平台的 CPU 资源在线部署多个开源大模子处事,这些处事不仅为客户应用提供了顽强的大模子支捏,还不祥用于千帆大模子平台 prompt 优化工程等相干任务场景。
●高性能推理:借助英特尔® 至强® 可扩张处理器和 xFT 推清晰决有缱绻,千帆大模子平台不祥罢了大幅提高的推感性能。这包括缩短推理时延,提高处事反馈速率,以及增强模子的合座婉曲智力。
●定制化部署:千帆大模子平台提供了纯简直部署选项,允许用户阐明具体业务需求弃取最适宜的硬件资源成就,从而优化大模子在实质应用中的阐扬和效果。
4、写在终末
对于千帆大模子平台来说,英特尔匡助其科罚了客户在大模子应用过程中对计较资源的需求,进一步提高了大模子的性能和遵循,让用户以更低的本钱获取高质地的大模子处事。
大模子生态要思捏续不休地往前演进,无疑要靠一个个实打实的小业务落地把悉数这个词生态构建起来,英特尔相连千帆大模子平台恰是在匡助企业以最少的本钱落地大模子应用,让他们在探索大模子应用时找到了更具效价比的选项。
改日,两边策动在更高性能的至强® 居品支捏、软件优化、更多模子支捏以及要点客户相连支捏等方面张开深化相助。旨在提高大模子运行遵循和性能,为千帆大模子平台提供更完善的软件支捏,确保用户能实时运用最新的本事遵循,从而加快大模子生态捏续上前。
更多对于至强® 可扩张处理器为千帆大模子平台推理加快的信息nt 动漫,请点击英特尔官网查阅。